


Temps de lecture estimé: 6 minutes
L’intelligence artificielle générative est partout, et de plus en plus d’entreprises veulent leur application IA. Parfois sans vraiment savoir pourquoi, c’est devenu presque une priorité. Certaines entreprises vont même jusqu’à demander — voire imposer — à leurs prestataires l’utilisation de l’IA dans leurs processus.
L’industrie n’est pas exemptée de cette tendance.
Mais entre les annonces marketing et la réalité d’un environnement industriel sensible, il y a un monde.
En tant que consultant MES / Industrie 4.0, travaillant avec la solution DELMIA Apriso de Dassault Systèmes, je me suis posé une question simple :
Comment intégrer un LLM dans un environnement industriel tout en respectant les contraintes de sécurité, de confidentialité des données, et souvent sur des architectures isolées du monde extérieur ?
J’ai donc développé un Proof of Concept, puis amorcé une phase d’industrialisation.
Voici le retour d’expérience complet.
Le problème : IA et environnement industriel ne font pas toujours bon ménage
Dans l’industrie :
- Les données sont sensibles
- Les bases contiennent des informations critiques (production, qualité, traçabilité)
- Les systèmes sont souvent isolés ou fortement sécurisés
- Les équipes IT interdisent l’exposition vers des API externes
Impossible donc d’utiliser une API OpenAI ou autre service cloud public.
La seule option viable :
👉 LLM local, maîtrisé, hébergé en interne.
Le POC : simple, imparfait, mais encourageant
Sur mon temps libre, je me suis amusé à mettre en place un prototype rapide pour explorer les possibilités et valider la faisabilité d’un LLM dans un contexte industriel.
L’idée était simple :
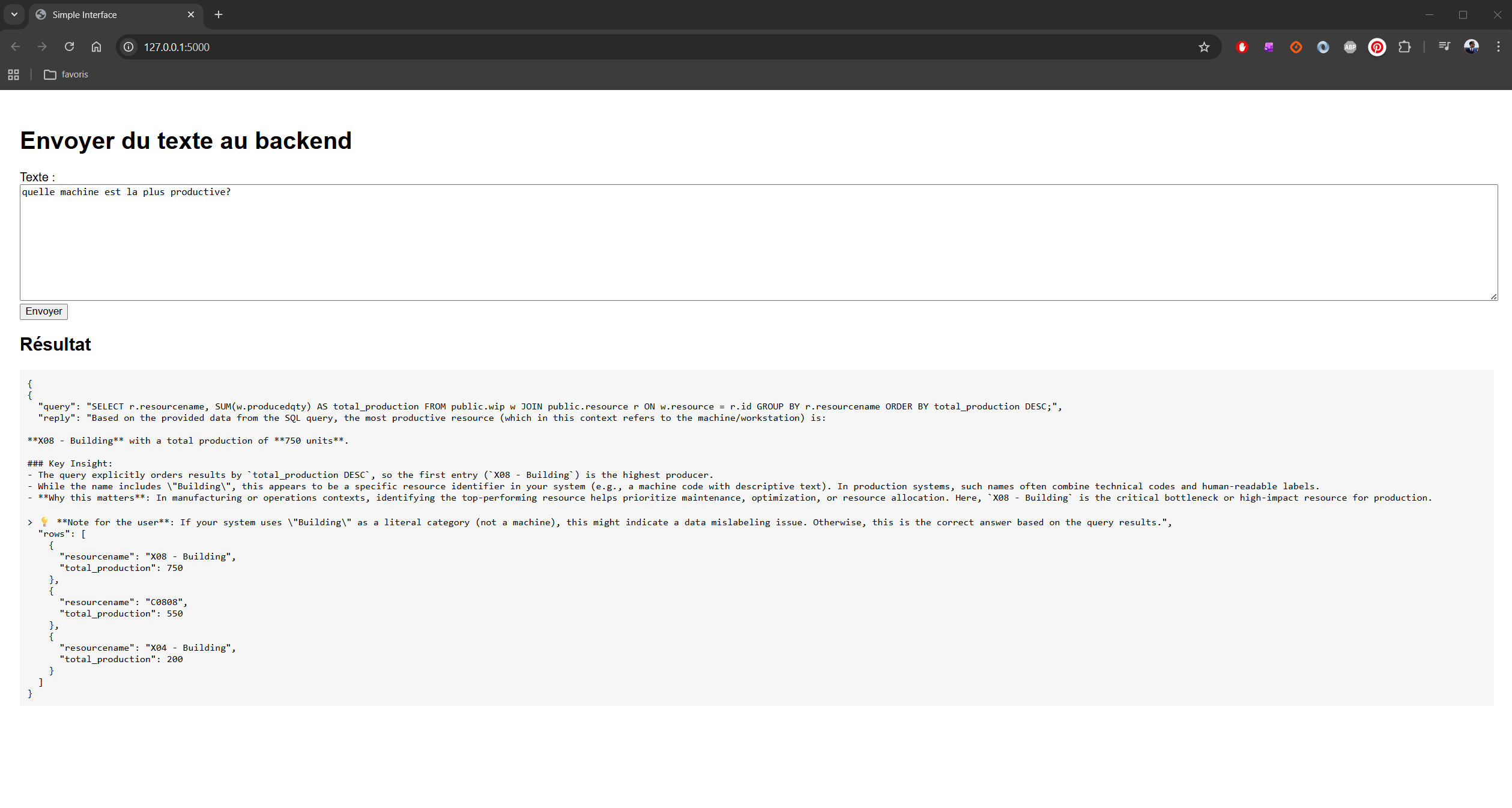
- L’utilisateur pose une question libre dans une textarea.
- Le LLM génère une requête SQL.
- La requête est exécutée sur la base MES.
- Les résultats sont renvoyés au LLM.
- Le LLM produit une analyse en langage naturel.
Schéma logique :
Question utilisateur
↓
LLM → Génération SQL
↓
Base MES
↓
Résultats bruts
↓
LLM → Analyse métier
↓
Réponse finaleExemple de question :
« Quels sont les ordres de production en retard sur la ligne 3 cette semaine ? »
Le modèle devait :
- Identifier les tables pertinentes
- Générer une requête SQL cohérente
- Interpréter les résultats
Stack utilisée
- Python + Flask pour l’interface minimaliste
- Ollama
- Llama 3
- Base Postgres SQL avec un mini modèle de données reproduisant quelques tables (équipements, opérateurs, commandes et production, downtime). L’architecture cible sera le vrai modèle de 1200 tables, en Oracle ou SQL Server suivant le client.
Machine utilisée
- i7
- RTX 2070
- 16 Go RAM
Clairement sous-dimensionné pour un vrai usage industriel.
Mais …. je n’ai que ça 😅 donc pour expérimenter sur mon temps libre, c’était suffisant pour valider les concepts.
Les limites du POC
Le prototype fonctionnait… mais soyons honnêtes : c’était loooooin d’être parfait !
Je l’ai présenté, et nous avons décidé d’allouer du temps pour le développer correctement.
Le POC était vraiment une version alpha, loin d’un projet solide.
- Ollama a été utilisé pour sa simplicité de mise en place, mais c’est le niveau 0 de l’utilisation d’un LLM local.
- Les temps de réponse étaient loooongs, mais ma machine (i7 + RTX 2070 + 16 Go RAM) n’est clairement pas faite pour ça.
- Mon modèle de 5 tables avec 20 enregistrements par table était simpliste. La documentation de ce mini-modèle pouvait être passée directement dans le prompt.
Avec le vrai modèle industriel (millions de lignes, 1200 tables), il sera impossible de passer toutes les informations dans le prompt. Il faudra donc utiliser un RAG (Retrieval Augmented Generation). - Un gros travail de prompt engineering sera nécessaire pour cadrer les requêtes et les réponses. Actuellement, je n’ai mis aucune sécurité ni contrôle en place sur les requêtes générées ou le type de questions posées.
Performance
Avec Ollama :
- Latence élevée
- Saturation rapide du GPU
- Difficulté à gérer de gros prompts
Hallucinations SQL
Le modèle pouvait :
- Inventer des colonnes
- Supposer des relations inexistantes
- Générer des requêtes non exécutables
Pas de contexte métier
Sans documentation complète :
- Le modèle ne comprenait pas toujours la logique métier
- Il manquait la connaissance fonctionnelle spécifique au client
Aucun cadre de sécurité SQL
Risque potentiel :
- Génération de
DELETE/UPDATEpar erreur - Requêtes trop lourdes
- Absence de limitation ou de contrôle
👉 En résumé : le POC validait la faisabilité, mais pas la robustesse.
C’était un point de départ pour envisager une version industrialisée, sécurisée et performante.
Passage à l’industrialisation
Je suis content : à l’heure où j’écris ces lignes, et après présentation du POC, la décision a été prise de passer à une phase d’implémentation plus sérieuse et d’allouer des ressources.
À moi les GPU et les Go de RAM ! 🤣
La version beta sera probablement organisée ainsi :
Infrastructure cible :
- VM Azure NCasT4_v3 (GPU T4) pour nos tests (l’infra client sera adaptée ensuite)
- Linux
- Backend Python (FastAPI ou Flask)
- Moteur d’inférence optimisé : vLLM, adieu Ollama !
- Base vectorielle : Qdrant
- Orchestration LLM : LangChain
- Base de données : Oracle ou Microsoft SQL Server selon le client
Pourquoi abandonner Ollama ?
Ollama est excellent pour expérimenter, mais pas pour la production.
La cible devient donc vLLM, beaucoup plus adapté à un environnement serveur :
- Gestion fine du GPU
- Optimisation du batching
- Montée en charge efficace
- Contrôle mémoire précis
Nouvelle architecture cible
Architecture logique :
Utilisateur
↓
API FastAPI
↓
Orchestration (LangChain)
↓
├── RAG (Qdrant)
├── Connexion Oracle / SQL Server
└── LLM via vLLM
Le vrai game changer : le RAG appliqué au pilotage de la production
Un LLM seul ne suffit pas.
Dans mon prototype, j’avais documenté le mini-modèle et injecté cette documentation dans le prompt system du LLM.
Avec quelques dizaines de lignes, ça passait. Mais dans un vrai projet industriel :
- Millions de lignes
- 1200 tables
- Documentation complexe
…Impossible de tout passer dans le prompt. Il faut donc mettre en place un RAG (Retrieval Augmented Generation).
Étapes :
- Extraction de la documentation technique et fonctionnelle
- Découpage (chunking)
- Génération d’embeddings
- Indexation dans Qdrant
- Injection des contextes pertinents dans le prompt
Résultat :
- Moins d’hallucinations
- Requêtes SQL plus réalistes
- Réponses alignées avec le métier
Travail sur le prompt engineering en contexte industriel
Le prompt devient un composant critique, et même un métier à part entière : le prompt engineer.
Un gros travail de cadrage et d’optimisation est nécessaire pour rester dans le cadre fonctionnel du MES (Manufacturing Execution System).
Contraintes minimales à imposer :
- SELECT uniquement
- Interdiction explicite de DELETE / UPDATE
- Utilisation exclusive des tables autorisées
- Limitation du nombre de lignes retournées
- Format structuré obligatoire pour la sortie
Exemple d’instruction :
Tu es un assistant expert en base MES.
Tu ne réponds qu’aux questions relatives au contexte industriel.
Tu ne génères que des requêtes SELECT valides.
Tu n’inventes jamais de colonnes.
Si l’information est insuffisante, demande une clarification.
Le travail sur le prompt réduit drastiquement les erreurs et permet d’avoir des réponses plus fiables et cohérentes.
Les défis réels et le challenge
Intégrer un LLM en industrie pose de vrais problèmes :
- La qualité des données impacte directement celle des réponses
- Les modèles ne comprennent pas intuitivement les modèles relationnels complexes
- Les performances GPU doivent être surveillées
- Le coût d’infrastructure est réel
- L’évaluation qualitative est difficile
Un LLM n’est pas magique.
Il nécessite :
- Architecture
- Contrôle
- Supervision
- Garde-fous
Ce que cela change concrètement
Ce type d’outil peut permettre :
- Exploration rapide des données de production
- Support aux analystes métier
- Réduction de la dépendance aux équipes IT pour requêtes ad hoc
- Assistance à la compréhension des KPI complexes
Mais il ne remplace pas :
- L’expertise métier
- L’architecture MES
- La rigueur des processus industriels
Conclusion
Bon, c’est vrai, parfois je me demande… quand on voit l’énergie dépensée en temps, en ressources et en argent pour implémenter de l’IA, alors que parfois un développement classique aurait pu produire un résultat tout aussi “magique” pour l’utilisateur final… bref.
Tout l’enjeu ici est de ne pas ajouter de l’IA parce que c’est à la mode, mais bien de créer un outil capable d’améliorer la vie des opérateurs et managers dans les usines. L’objectif : un produit réellement utile aux équipes terrain, robuste et sécurisé.
Au-delà de ça, ce projet m’a permis de constater une chose importante :
L’IA générative en industrie n’est pas une question de modèle.
C’est une question d’architecture.
Entre un POC sur un PC portable et une architecture GPU avec RAG, il y a un véritable travail d’ingénierie.
J’ai beaucoup avancé sur ce projet sur mon temps personnel, et j’ai hâte de continuer sa mise en place (qui, pour des raisons de secret professionnel, ne sera probablement pas documentée ici 😉).
En attendant, je te dis à bientôt pour de nouvelles aventures !