
Temps de lecture estimé: 6 minutes
NestJS + Next.js + PostgreSQL + LLM + Gitlab CI/CD + Docker
J’ai laissé un LLM gérer un portefeuille fictif pendant une semaine.
Résultat : ce n’est pas encore Warren Buffett 🤣
Après avoir expérimenté l’intégration d’un LLM dans un contexte industriel, j’ai voulu continuer à explorer l’utilisation concrète de l’IA dans un projet personnel.
Cette fois-ci, j’ai choisi un cas d’usage différent : concevoir un bot de trading simulé, capable d’analyser un portefeuille fictif et de proposer des décisions d’investissement (achat / vente / conservation) à l’aide d’un LLM (sans analyses plus poussées de données financières, analyse de courbe ou autres indicateurs, juste une IA et un simple prompt).
L’objectif était de concilier 2 centre d’intérêt, le développement et l’investissement. Créer et tester un système de trading fictif dans le but de voir les résultat et éventuellement le brancher à un vrai Broker… bon spoiler alert: les résultats du LLM ne sont pas très rentable pour l’instant
au dela de faire un peu joujou, le but technique était de :
- Concevoir une architecture 3-tiers propre
- Approfondir un backend en NestJS
- Intégrer un LLM dans une logique métier structurée
- Mettre en place une authentification JWT
- Ajouter des tests E2E
- Dockeriser l’ensemble
- Déployer automatiquement via CI/CD sur mon homelab
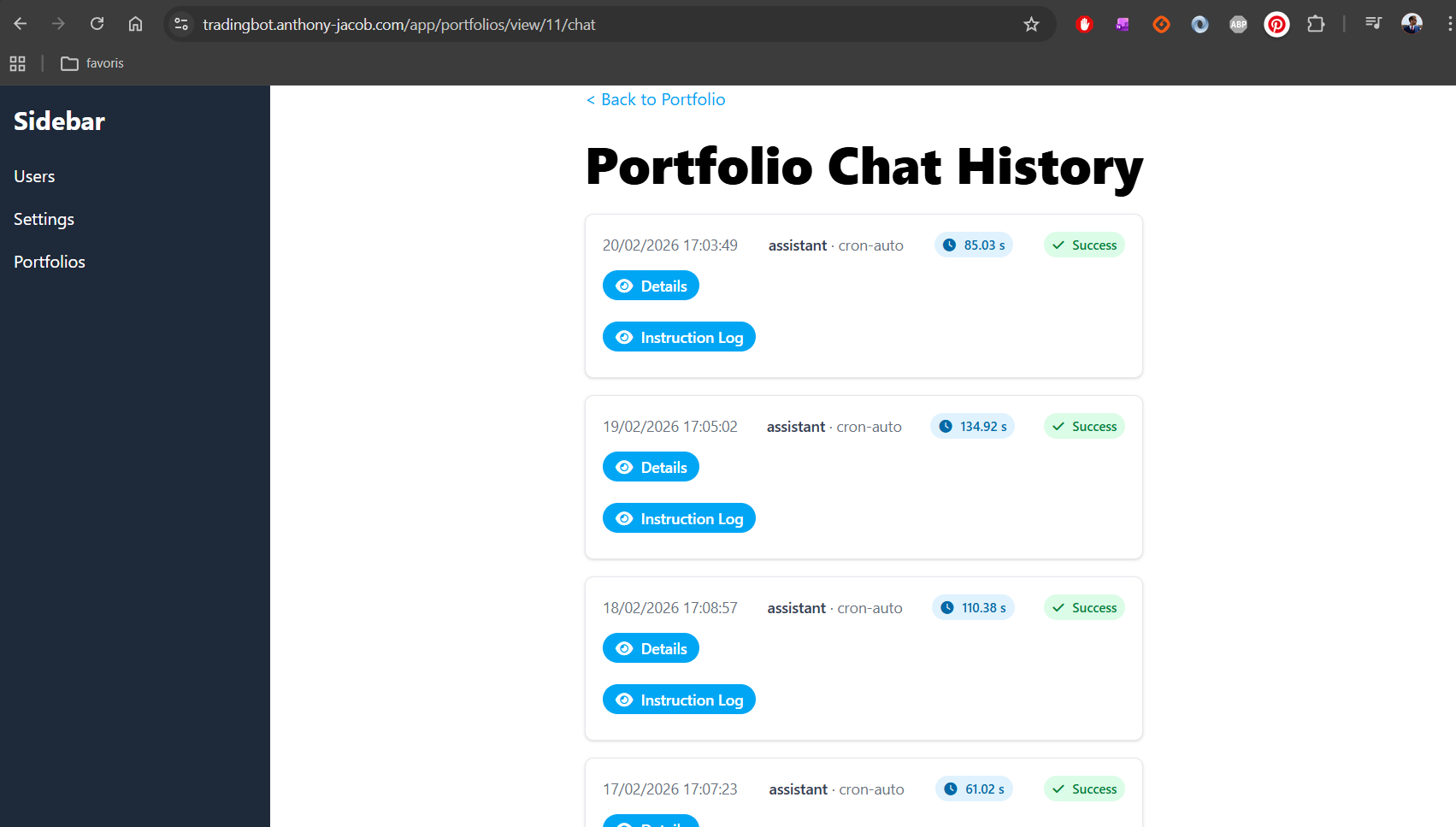
Démo et code public
n’hésite pas à aller faire un tour sur https://tradingbot.anthony-jacob.com et tu pourras te logger avec l’utilisateur
tradingbot@demo.com / uCNWgUsDshBJd5y
pour les repos, c’est disponible sur
https://gitlab.anthony-jacob.com/anthony.jacob/tradingbot-front/
https://gitlab.anthony-jacob.com/anthony.jacob/tradingbot-api
⚠️Disclaimer
alors déjà coté investissement: Ce projet est avant tout un projet d’expérimentation et de démonstration. Il n’a pas vocation à être utilisé en production ni à servir de conseil financier.
Ensuite niveau application, oui ça reste grandement perfectible, oui l’UX n’est pas parfaite, oui ce n’est pas traduit, oui le code pourrait être refacto/optimisé et plus clean, oui il peut rester quelques bugs à la marge!!!
Mais bon J’y consacre une partie de mon temps libre et on avance pas aussi vite sur son temps libre qu’au travail 8 à 9h par jour 5j/7.
Donc à un moment, il faut accepter d’avancer plutôt que de viser la perfection absolue.
Architecture globale
Le projet repose sur une architecture 3-tiers classique :
PostgreSQL
↑
NestJS API
↑
Next.js Frontend
Et des intégrations externes :
- API stockdata pour récupérer les données de marché (free plan limité à 100 requêtes par jour)
- LLM (Grok / xAI) pour les décisions d’investissement
Chaque couche a une responsabilité claire :
- Base de données : persistance des données: utilisateurs, portfolios, positions
- API NestJS : logique métier, orchestration LLM, sécurité
- Frontend Next.js : interface utilisateur
Backend : découverte et utilisation de NestJS
Pour ce projet, j’ai choisi NestJS, que je découvrais à cette occasion.
Dans l’idée, pas de grande révolution conceptuelle. NestJS reste dans l’esprit des frameworks MVC classiques que l’on retrouve dans d’autres langages. On y retrouve tout le nécessaire pour structurer proprement une application backend :
- Des routes via des Controllers
- Une logique métier encapsulée dans des Services injectables
- Une organisation claire par Modules
- Un système robuste de Dependency Injection
- Des décorateurs puissants et très pratiques
- Des guards, interceptors et middlewares pour structurer les flux
Bref, un framework complet, structurant et cohérent.
Architecture logique du backend
L’API joue un rôle central dans le projet. Elle orchestre les interactions entre plusieurs composants :
- La base PostgreSQL
- L’API financière StockData pour récupérer les données des tickers
- Le LLM (Grok / xAI) pour la prise de décision
- Le frontend Next.js
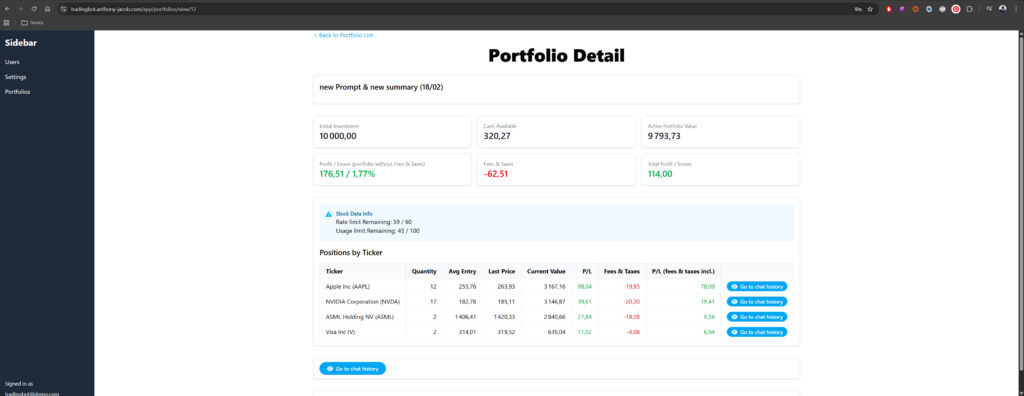
Fonctionnalités implémentées
L’API expose plusieurs domaines fonctionnels :
- Gestion des utilisateurs
- Gestion des portfolios
- Gestion des positions ouvertes
- Gestion des positions fermées
- Interaction avec le LLM pour prise de décision
- Authentification JWT avec access token + refresh token
- RBAC minimal (Role-Based Access Control)
L’objectif était d’avoir un système réaliste minimal.
Base de données : PostgreSQL + TypeORM
J’ai utilisé PostgreSQL avec TypeORM.
Modèle simplifié :
- User
- Portfolio
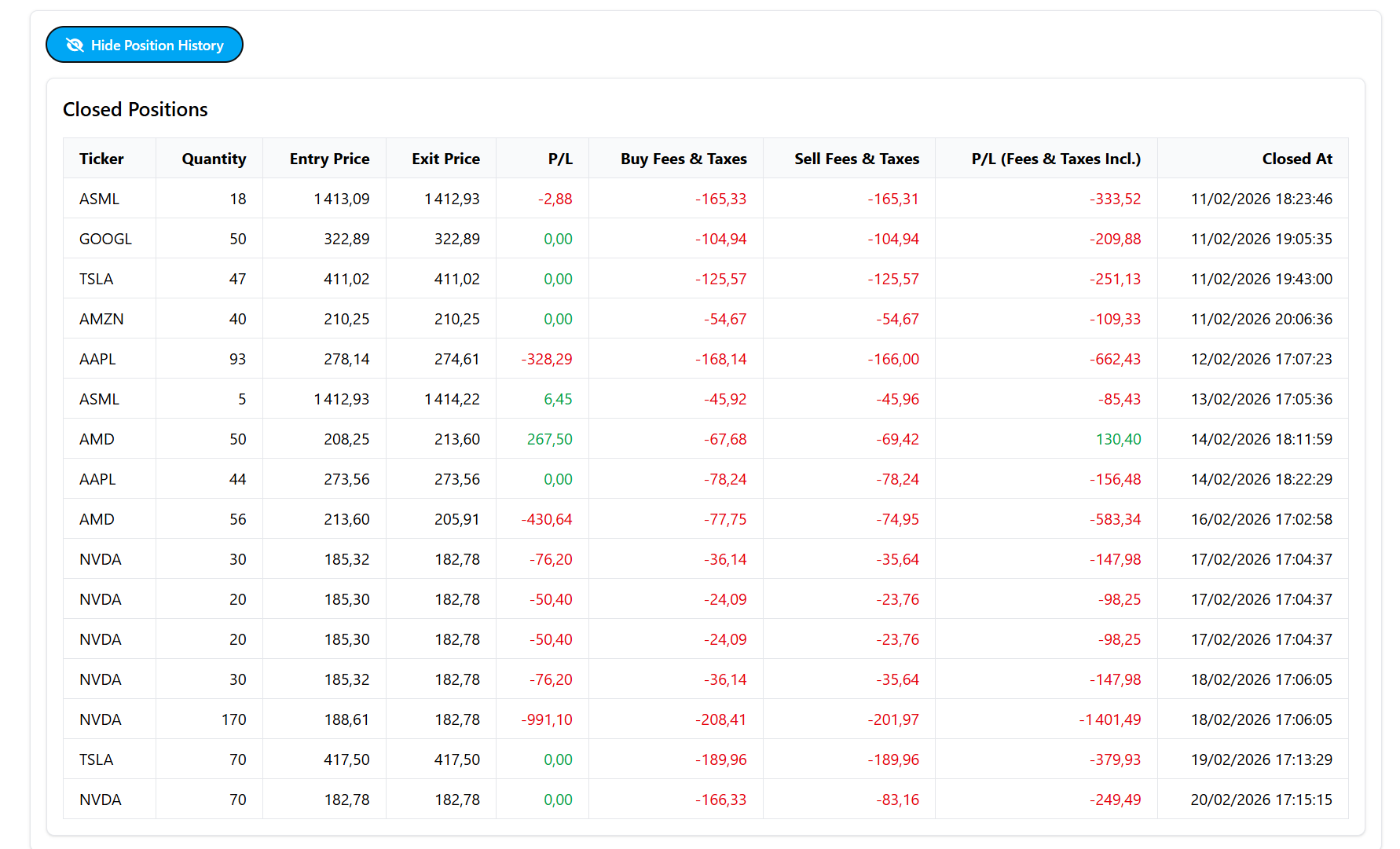
- OpenPosition
- ClosedPosition
- Historique de chat et instructions
Intégration du LLM dans la logique métier
Quotidiennement, un job automatique:
- Récupère pour chaque portfolio les des données du portfolio (cash dispo et position actualisé avec les prix du marché marché via Stockdata)
- Construction d’un prompt “trading guru” incluant les données du portfolio
- premier Envoi au LLM (Grok / xAI)
- premier Parsing de la réponse avec Décision BUY / SELL
- check du prix du marché pour les actions BUY (Grok n’est pas très doué pour donner les prix exact des actions au moment où on lui demande)
- deuxieme Envoi au LLM (Grok / xAI) avec les vrais prix pour demander une confirmation de sa strategie
- deuxieme parsing de la réponse et réalisation des instructions de BUY / SELL
- Enregistrement du chat et des instruction en base
Authentification : JWT access + refresh token
L’authentification repose sur un Access token (court terme) et un Refresh token (rotation)
Les routes sensibles sont protégées par des guards NestJS tant pour l’authentification et le token JWT que pour les droits en fonction des roles (RBAC).
L’objectif était d’avoir un système réaliste et sécurisé, proche d’un environnement de prod.
Tests E2E
J’ai ajouté des tests end-to-end avec Supertest sur quelques cas de base (principalement la gestion d’utilisateur et l’authentification) .
Frontend : Next.js + Tailwind
Côté frontend, j’ai utilisé Next.js et Tailwind.
Je dois avouer que je préfère Bootstrap — peut-être parce que je ne maîtrise pas encore totalement Tailwind. Mais l’objectif était aussi de sortir de ma zone de confort.
Fonctionnalités front :
- Authentification
- gestion des utilisateurs
- Visualisation du portfolio
- Positions ouvertes / fermées
- Historique des décisions IA
Dockerisation & CI/CD
le front et le back sont :
- Versionné sur mon gitlab
- Buildé dans une image Docker
- Déployable indépendamment
Le déploiement est automatisé via GitLab CI/CD au travers d’une pipeline simple :
- Test e2e
- Build de l’image Docker & Push sur le registry gitlab
- Déploiement sur mon homelab
limites observées avec le LLM
L’intégration d’un LLM dans une logique financière met rapidement en évidence quelques limites non négligeables.
Même si le modèle est performant dans l’analyse textuelle, il n’est ni un moteur de calcul fiable, ni une source de vérité sur des données temps réel.
1. Hallucination des prix
Le modèle proposait régulièrement des prix incohérents ou obsolètes.
Il n’a évidemment aucun accès au marché temps réel.
D’où l’intégration d’une API externe (StockData) pour garantir la véracité des données utilisées pour les décisions.
2. Mauvaise gestion des montants disponibles
Autre comportement observé : le LLM pouvait proposer d’acheter un nombre d’actions incohérent avec les fonds réellement disponibles.
Par exemple :
- Prix approximatif incorrect
- Mauvais calcul du total investi
- Décalage entre cash disponible et volume proposé
La raison est simple :
Un LLM n’est pas un moteur de calcul déterministe.
Il prédit du texte en fonction de probabilités, il ne maintient pas un état mathématique rigoureux.
Dans un contexte financier, cette limite devient rapidement visible.
Il prédit du texte, il ne maintient pas un état mathématique rigoureux.
3. Prise en compte partielle des frais
Finalement pour les mêmes raisons que ci dessus, même en lui précisant des frais de transaction (0,0065%), ceux-ci étaient rarement correctement intégrés dans ses décisions.
Les frais semblaient “connus” par le modèle, mais insuffisamment pondérés dans la stratégie.
Dans une version suivante, j’ai donc :
- Injecté les frais déjà payés
- Injecté les frais estimés en cas de vente
- Rappelé explicitement leur impact sur la performance globale
- Insisté dans le prompt sur la nécessité d’optimiser en tenant compte des coûts cumulés
Cela a permis d’améliorer légèrement la cohérence des décisions.
4. Comportement “yoyo”
Un comportement inattendu mais fréquent :
- Achat J
- Vente à perte J+1
- Rachat J+2
- Revente à perte J+3
Sans prise en compte du coût cumulé des frais.
Le LLM réagit principalement à l’état courant du portefeuille.
Il ne construit pas spontanément une cohérence stratégique dans le temps.
J’ai dû adapter le prompt pour contraindre davantage la stabilité des décisions et limiter les rotations inutiles.
Limitation des problèmatiques
Je me suis aperçu de ces coquilles au fur et à mesure de l’implémentation. le flow décris dans Intégration du LLM dans la logique métier est le flux à l’heure où j’ecris ces lignes mais au commencement je n’avais qu’un aller retour entre mon backend et le LLM.
quelques points m’ont permit de limiter les problèmes:
- fournir plus de données au LLM (frais déjà payés, frais hypothétique futur)
- restructuration / recadrage du prompt pour insister sur les frais et l’effet Yoyo
- 2 aller retours au LLM pour lui faire confirmer ses actions en lui fournissant les prix actualisés des actions
Conclusion
Ce projet m’a permis de travailler plusieurs dimensions en parallèle :
- Backend structuré
- Authentification sécurisée
- Intégration API externe
- Orchestration LLM
- Tests E2E
- Docker
- CI/CD
- Déploiement
Au-delà de l’IA, ce qui m’intéresse, c’est l’intégration propre dans une architecture complète.
Un LLM seul ne vaut rien.
Ce qui compte, c’est la manière dont il est intégré dans un système cohérent.
Si le projet vous intéresse, les repos sont disponibles, et la démo est en ligne.
Les retours sont les bienvenus.
Et en attendant, je te dis à bientôt pour de nouvelles expérimentations 👋